2023. 4. 13. 02:42ㆍC언어
🔎 Malloc Lab
Carnegie Mellon University의 Malloc Lab 과제
- C 프로그램을 위한 malloc, free 및 realloc 루틴의 버전을 직접 작성하는 과제이다.
- 주어진 파일을 초기 상태에서 테스트를 해보면 아래와 같이
out of memory에러가 발생한다.
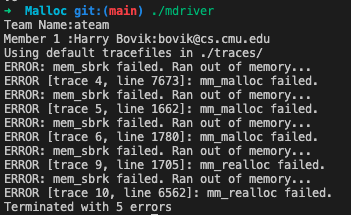
- implicit list 방식대로 malloc을 구현해서 이
out of memory에러를 없애는 과제이다. - 추가적으로 explicit list와 seglist 등을 활용해서 점수를 높일 수 있다.
- dynamic storage allocator는 네 가지 기능으로 구성된다. 이 함수들은 mm.h에 선언되어 있고, mm.c에서 정의한다.
int mm_init(void); // 초기화
void *mm_malloc(size_t size); // 할당
void mm_free(void *ptr); // 해제
void *mm_realloc(void *ptr, size_t size); // 재할당- 초기의 mm.c 파일에는 가장 간단한 형태의 malloc 패키지가 구현되어 있다. 이 함수들을 수정해서 아래 요구사항을 만족시키도록 한다. (필요하다면 다른 private static 함수를 정의해도 된다.)
- 배열, 구조체, 트리, 리스트와 같은 정적인 복합 데이터 구조체를 정의할 수 없다.
- 처리량과 이용도 사이에는 trade-off가 존재하며, 이 두 가지 목표 사이에서 적절한 균형을 찾아야 한다.
요구사항
1) mm_init
int mm_init(void);
- 초기 힙 영역을 할당한다.
2) mm_malloc
int mm_init(void);
- mm_malloc 루틴은 적어도 주어진
size크기의 블록에 할당되어야 한다. - 주어진 크기보다 큰 블록을 할당할 수 있으며, 반환된 포인터는 적어도 요청한 크기보다 큰 블록에 대한 포인터를 가리켜야 한다.
- 할당된 블록 전체는 힙 영역 내에 있어야 하며 다른 할당된 청크와 겹치지 않아야 한다.
- 이 과제는 표준 라이브러리(libc)에서 제공하는 버전의 malloc과 비교하여 평가된다.
libc의 malloc은 8바이트에 맞춰 정렬된 페이로드 포인터를 반환하므로, mm_malloc 함수를 8바이트에 맞춰 정렬된 포인터를 반환하도록 구현해야 한다.
3) mm_free
void mm_free(void *ptr);
- ptr이 가리키는 블록을 해제한다.
- 아직 해제되지 않았고, 이전에 mm_malloc 또는 mm_realloc 호출에서 반환된 ptr이 전달된 경우에만 작동한다.
4) mm_realloc
void *mm_realloc(void *ptr, size_t size);
- 아래의 조건을 만족하는 주어진
size크기보다 같거나 큰 영역으로 할당된 영역에 대한 포인터를 반환한다.ptr이 NULL인 경우- mm_malloc(size)과 동일하다.
size가 0인 경우- mm_free(ptr)과 동일하다.
ptr이 NULL이 아닌 경우ptr은 이전에 mm_malloc 또는 mm_realloc 호출에서 반환된 포인터여야 한다.ptr이 가리키는 이전 블록의 크기를size크기로 변경하고 새 블록의 주소를 반환한다.- 새 블록의 주소는 이전 블록과 동일할 수도 있고 다를 수도 있다.
(구현 방식, 이전 블록 내부 단편화의 양, 요청 크기에 따라 다르다.) - 새 블록은 이전 블록의 크기만큼은 이전 블록의 내용과 동일하고, 나머지 영역은 초기화되지 않는다.
1. Implicit List
Github에서 'Implicit List' 전체 코드 보기
🧮 Score: 54점 (이용도 44 + 처리량 9)
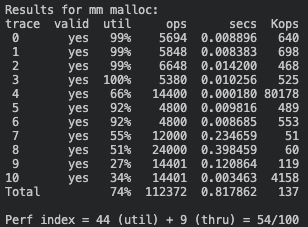
💡 Implicit List 기본 아이디어
1) 블록 할당
- 블록의
사용 여부와 블록의사이즈를 각 블록 내부의 header 및 footer에 저장한다. - 리스트를 처음부터 검색해서
크기가 맞는 첫번째 가용 블록을 선택한다. (First fit) - 선택한 가용 블록이 사용할 사이즈보다 큰 사이즈를 가지고 있다면,
필요한 사이즈만큼만 사용하고나머지는 분할하여 또다른 가용 블록으로 남겨둔다.
2) 블록 반환
- 블록이 반환되면 주소상으로 인접한 블록을 확인해서 빈 블록이 있다면 연결하여 더 큰 블록으로 만들어서 가용 블록으로 만든다.
🖥 Implicit List 구현
1) 기본 상수 및 매크로 정의
- 자주 사용하게 될 상수와 매크로를 미리 정의한다.
/* 기본 상수 */
#define WSIZE 4 // word size
#define DSIZE 8 // double word size
#define CHUNKSIZE (1 << 12) // 힙 확장을 위한 기본 크기 (= 초기 빈 블록의 크기)
/* 매크로 */
#define MAX(x, y) (x > y ? x : y)
// size와 할당 비트를 결합, header와 footer에 저장할 값
#define PACK(size, alloc) (size | alloc)
// p가 참조하는 워드 반환 (포인터라서 직접 역참조 불가능 -> 타입 캐스팅)
#define GET(p) (*(unsigned int *)(p))
// p에 val 저장
#define PUT(p, val) (*(unsigned int *)(p) = (val))
// 사이즈 (~0x7: ...11111000, '&' 연산으로 뒤에 세자리 없어짐)
#define GET_SIZE(p) (GET(p) & ~0x7)
// 할당 상태
#define GET_ALLOC(p) (GET(p) & 0x1)
// Header 포인터
#define HDRP(bp) ((char *)(bp)-WSIZE)
// Footer 포인터 (🚨Header의 정보를 참조해서 가져오기 때문에, Header의 정보를 변경했다면 변경된 위치의 Footer가 반환됨에 유의)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
// 다음 블록의 포인터
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp)-WSIZE)))
// 이전 블록의 포인터
#define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(((char *)(bp)-DSIZE)))2) 힙 생성하기
- 초기에 ‘정렬 패딩(unused) + 프롤로그 header + 프롤로그 footer + 에필로그 header’를 담기 위해 4워드 크기의 힙을 생성한다.
- 생성 후 CHUNKSIZE만큼 추가 메모리를 요청해 힙의 크기를 확장한다.
int mm_init(void)
{
// 초기 힙 생성
char *heap_listp;
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *)-1) // 4워드 크기의 힙 생성, heap_listp에 힙의 시작 주소값 할당
return -1;
PUT(heap_listp, 0); // 정렬 패딩
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 Header
PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 Footer
PUT(heap_listp + (3 * WSIZE), PACK(0, 1)); // 에필로그 Header: 프로그램이 할당한 마지막 블록의 뒤에 위치하며, 블록이 할당되지 않은 상태를 나타냄
// 힙을 CHUNKSIZE bytes로 확장
if (extend_heap(CHUNKSIZE / WSIZE) == NULL)
return -1;
return 0;
}3) 가용 블록에 할당하기
- 사이즈 조정 : 할당 요청이 들어오면(malloc 함수 호출) 요청 받은
size를 조정한다.
👉🏻 블록의 크기는 적어도 16바이트 이상이어야 한다. (header 4bytes + footer 4bytes + payload 8bytes)
👉🏻 블록의 크기는 8의 배수이어야 하므로(정렬 요건), 항상 8의 배수가 되도록 올림 처리한다. - 가용 블록 검색 : 조정된 사이즈를 가지고 있는 블록을 검색한다. (
find_fit함수 호출)
적합한 블록을 찾았다면 해당 블록에 할당한다. (place함수 호출) - 힙 확장 : 적합한 블록이 없는 경우, 추가 메모리를 요청해 힙을 확장한다. (
extend_heap함수 호출)
힙을 확장하고 나서 받은 새 메모리 블록에 할당한다. (place함수 호출)
void *mm_malloc(size_t size)
{
size_t asize; // 조정된 블록 사이즈
size_t extendsize; // 확장할 사이즈
char *bp;
// 잘못된 요청 분기
if (size == 0)
return NULL;
/* 사이즈 조정 */
if (size <= DSIZE) // 8바이트 이하이면
asize = 2 * DSIZE; // 최소 블록 크기 16바이트 할당 (헤더 4 + 푸터 4 + 저장공간 8)
else
asize = DSIZE * ((size + DSIZE + DSIZE - 1) / DSIZE); // 8배수로 올림 처리
/* 가용 블록 검색 */
if ((bp = find_fit(asize)) != NULL)
{
place(bp, asize); // 할당
return bp; // 새로 할당된 블록의 포인터 리턴
}
/* 적합한 블록이 없을 경우 힙확장 */
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize / WSIZE)) == NULL)
return NULL;
place(bp, asize);
return bp;
}
가용 블록 검색
- 힙의 첫번째 블록부터 탐색을 시작한다.
- 가용 상태이면서 현재 필요한 크기인
asize를 담을 수 있는 블록을 찾을 때까지 탐색을 이어간다. (First-fit)
static void *find_fit(size_t asize)
{
void *bp = mem_heap_lo() + 2 * WSIZE; // 첫번째 블록(주소: 힙의 첫 부분 + 8bytes)부터 탐색 시작
while (GET_SIZE(HDRP(bp)) > 0)
{
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp)))) // 가용 상태이고, 사이즈가 적합하면
return bp; // 해당 블록 포인터 리턴
bp = NEXT_BLKP(bp); // 조건에 맞지 않으면 다음 블록으로 이동해서 탐색을 이어감
}
return NULL;
}
할당
- 선택한 가용 블록이 사용할 사이즈보다 큰 사이즈를 가지고 있다면,
필요한 사이즈만큼만 사용하고나머지는 분할하여 또다른 가용 블록으로 남겨둔다.
static void place(void *bp, size_t asize)
{
size_t csize = GET_SIZE(HDRP(bp)); // 현재 블록의 크기
if ((csize - asize) >= (2 * DSIZE)) // 차이가 최소 블록 크기 16보다 같거나 크면 분할
{
PUT(HDRP(bp), PACK(asize, 1)); // 현재 블록에는 필요한 만큼만 할당
PUT(FTRP(bp), PACK(asize, 1));
PUT(HDRP(NEXT_BLKP(bp)), PACK((csize - asize), 0)); // 남은 크기를 다음 블록에 할당(가용 블록)
PUT(FTRP(NEXT_BLKP(bp)), PACK((csize - asize), 0));
}
else
{
PUT(HDRP(bp), PACK(csize, 1)); // 해당 블록 전부 사용
PUT(FTRP(bp), PACK(csize, 1));
}
}
힙 확장
- 추가 메모리 요청: 요청받은 words만큼 추가 메모리를 요청한다. (
mem_sbrk함수 요청) - 추가 메모리 요청에 성공하면 새로운 메모리를 새 빈 블록으로 만든다.
새 빈 블록의 header, footer를 초기화하고 힙의 끝부분을 나타내는 에필로그 블록의 헤더도 변경한다.
static void *extend_heap(size_t words)
{
char *bp;
// 더블 워드 정렬 유지
// size: 확장할 크기
size_t size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE; // 2워드의 가장 가까운 배수로 반올림 (홀수면 1 더해서 곱함)
if ((long)(bp = mem_sbrk(size)) == -1) // 힙 확장
return NULL;
PUT(HDRP(bp), PACK(size, 0)); // 새 빈 블록 헤더 초기화
PUT(FTRP(bp), PACK(size, 0)); // 새 빈 블록 푸터 초기화
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); // 에필로그 블록 헤더 초기화
return coalesce(bp); // 병합 후 coalesce 함수에서 리턴된 블록 포인터 반환
}4) 블록 반환하기
- 가용 상태로 변경: 블록의 상태를 할당 상태에서 가용 상태로 변경한다. (
PACK매크로 호출) - 병합 : 주소상으로 인접한 블록에 빈 블록이 있다면 연결한다. (
coalesce함수 호출)
void mm_free(void *bp)
{
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
}
병합
- 할당 여부 확인 : 인접 블록의 할당 상태를 확인한다. (
GET_ALLOC매크로 호출) - 병합 : 인접 블록 중 가용 상태인 블록이 있다면 현재 블록과 합쳐서 더 큰 하나의 가용 블록으로 만든다.
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp))); // 이전 블록 할당 상태
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); // 다음 블록 할당 상태
size_t size = GET_SIZE(HDRP(bp)); // 현재 블록 사이즈
if (prev_alloc && next_alloc) // 모두 할당된 경우
return bp;
else if (prev_alloc && !next_alloc) // 다음 블록만 빈 경우
{
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0)); // 현재 블록 헤더 재설정
PUT(FTRP(bp), PACK(size, 0)); // 다음 블록 푸터 재설정 (위에서 헤더를 재설정했으므로, FTRP(bp)는 합쳐질 다음 블록의 푸터가 됨)
}
else if (!prev_alloc && next_alloc) // 이전 블록만 빈 경우
{
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); // 이전 블록 헤더 재설정
PUT(FTRP(bp), PACK(size, 0)); // 현재 블록 푸터 재설정
bp = PREV_BLKP(bp); // 이전 블록의 시작점으로 포인터 변경
}
else // 이전 블록과 다음 블록 모두 빈 경우
{
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); // 이전 블록 헤더 재설정
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0)); // 다음 블록 푸터 재설정
bp = PREV_BLKP(bp); // 이전 블록의 시작점으로 포인터 변경
}
return bp; // 병합된 블록의 포인터 반환
}5) 재할당하기
예외 처리
- 인자로 전달 받은
ptr이 NULL인 경우에는 할당만 수행한다. (mm_malloc함수 호출) - 인자로 전달 받은
size가 0인 경우에는 메모리 반환만 수행한다. (mm_free함수 호출)
새 블록에 할당
- 할당 : 인자로 전달 받은
size만큼 할당할 수 있는 블록을 찾아 할당한다. (mm_malloc함수 호출)
데이터 복사
ptr이 가리키고 있던 블록이 가지고 있는 payload 크기를 구하고,
새로 할당할size보다 기존의 크기가 크다면 size로 크기를 조정한다.- 조정한
size만큼 새로 할당한 블록으로 데이터를 복사한다. (memcpy함수 호출)
기존 블록 반환
- 데이터 복사 후, 기존 블록의 메모리를 반환한다. (
mm_free함수 호출)
// 기존에 할당된 메모리 블록의 크기 변경
// `기존 메모리 블록의 포인터`, `새로운 크기`
void *mm_realloc(void *ptr, size_t size)
{
/* 예외 처리 */
if (ptr == NULL) // 포인터가 NULL인 경우 할당만 수행
return mm_malloc(size);
if (size <= 0) // size가 0인 경우 메모리 반환만 수행
{
mm_free(ptr);
return 0;
}
/* 새 블록에 할당 */
void *newptr = mm_malloc(size); // 새로 할당한 블록의 포인터
if (newptr == NULL)
return NULL; // 할당 실패
/* 데이터 복사 */
size_t copySize = GET_SIZE(HDRP(ptr)) - DSIZE; // payload만큼 복사
if (size < copySize) // 기존 사이즈가 새 크기보다 더 크면
copySize = size; // size로 크기 변경 (기존 메모리 블록보다 작은 크기에 할당하면, 일부 데이터만 복사)
memcpy(newptr, ptr, copySize); // 새 블록으로 데이터 복사
/* 기존 블록 반환 */
mm_free(ptr);
return newptr;
}😱 Implicit List 방식의 한계
- 블록 할당 시 힙을 처음부터 탐색해나가기 때문에 최악의 경우 탐색 시간이 전체 힙 블록의 수에 비례하게 된다.
- 따라서, 범용 할당기에는 적합하지 않고 블록의 수가 적은 특수한 경우에만 사용하는 것이 좋다.
- 이 한계점은 가용 블록들을 명시적 자료구조로 구성하는 Explict List 방식으로 개선할 수 있다.
2. Explicit List
Github에서 'LIFO 순서 정책' 전체 코드 보기
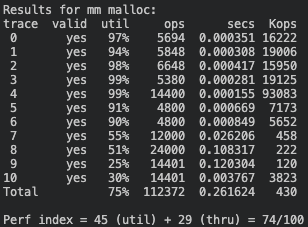
🧮 Explicit List 방식을 사용하면 블록 할당 시 전체 블록이 아닌 가용 블록만 탐색하게 되어서 Implicit List 방식에 비해 처리량이 3~5배 좋아졌다. 👍
(가용 리스트 정렬 방식에 따라 처리량 점수가 다르게 책정되었다.)
1) ’LIFO 순서’ 정책
Score: 85점 (이용도 45 + 처리량 40)
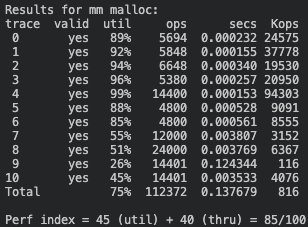
2) ‘주소 순서’ 정책
Score: 74점 (이용도 46 + 처리량 28)
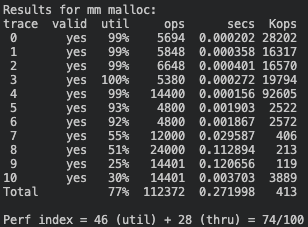
3) ‘사이즈 순서’ 정책
Score: 74점 (이용도 45 + 처리량 29)
💡 Explicit List 기본 아이디어
1) 명시적 가용 리스트 활용
- 가용 블록들을 리스트로 관리한다.
- 각 가용 블록 내에
predeccessor와successor포인터를 포함해 각 블록 간 연결 리스트 형태로 만든다. - 가용 블록들을 리스트로 관리하게 되면 할당할 때 힙 전체를 검색하는 것이 아니라, 가용 블록 리스트만 검색하게 되어 탐색 시간이 줄어든다.
2) 블록 할당
- 가용 블록 리스트를 처음부터 검색해서
크기가 맞는 첫번째 가용 블록을 선택한다. (First fit) - (Implict List와 동일) 선택한 가용 블록이 사용할 사이즈보다 큰 사이즈를 가지고 있다면,
필요한 사이즈만큼만 사용하고나머지는 분할하여 또다른 가용 블록으로 남겨둔다. - 할당하면서 또다른 가용 블록이 생기면 가용 리스트에 추가한다.
3) 블록 반환
- (Implict List와 동일) 블록이 반환되면 주소상으로 인접한 블록을 확인해서 빈 블록이 있다면 연결하여 더 큰 블록으로 만들어서 가용 블록으로 만든다.
- 만들어진 가용 블록을 정책에 맞게 가용 리스트에 삽입한다.
‘LIFO 순서’ 정책
- 만들어진 가용 블록을 가용 리스트의 첫부분에 삽입한다.
‘주소 순서’ 정책
- 만들어진 가용 블록을 가용 리스트에 삽입할 때 주소 오름차순으로 정렬이 되도록 위치를 탐색한 후 삽입한다.🖥 Explicit List 구현
1) 가용 블록 관련 매크로 정의
- Implicit List에서 사용하는 매크로 이외에 가용 블록을 찾기 위한 매크로를 추가한다.
- (이외의 매크로는 Implicit List와 동일하다.)
#define GET_SUCC(bp) (*(void **)((char *)(bp) + WSIZE)) // 다음 가용 블록의 주소
#define GET_PRED(bp) (*(void **)(bp)) // 이전 가용 블록의 주소2) 힙 생성하기
- 최소 크기 16bytes를 차지하는 더미 가용 블록을 초기에 할당한다.
- 가용 블록의 헤더 다음 워드에는 이전 가용 블록의 주소(predeccessor)를 할당하고, 그 다음 워드에는 다음 가용 블록의 주소(successor)를 할당한다.
- 더미 가용 블록의 이전/이후 가용 블록은 처음에는 존재하지 않으므로
predeccessor와successor를 NULL로 초기화한다.
- 더미 가용 블록의 이전/이후 가용 블록은 처음에는 존재하지 않으므로
- 가용 리스트의 첫번째 블록을 가리키는 포인터인
free_listp가 첫번째 가용 블록의 bp를 가리키도록 한다.
int mm_init(void)
{
// 초기 힙 생성
if ((free_listp = mem_sbrk(8 * WSIZE)) == (void *)-1) // 8워드 크기의 힙 생성, free_listp에 힙의 시작 주소값 할당(가용 블록만 추적)
return -1;
PUT(free_listp, 0); // 정렬 패딩
PUT(free_listp + (1 * WSIZE), PACK(2 * WSIZE, 1)); // 프롤로그 Header
PUT(free_listp + (2 * WSIZE), PACK(2 * WSIZE, 1)); // 프롤로그 Footer
PUT(free_listp + (3 * WSIZE), PACK(4 * WSIZE, 0)); // 첫 가용 블록의 헤더
PUT(free_listp + (4 * WSIZE), NULL); // 이전 가용 블록의 주소
PUT(free_listp + (5 * WSIZE), NULL); // 다음 가용 블록의 주소
PUT(free_listp + (6 * WSIZE), PACK(4 * WSIZE, 0)); // 첫 가용 블록의 푸터
PUT(free_listp + (7 * WSIZE), PACK(0, 1)); // 에필로그 Header: 프로그램이 할당한 마지막 블록의 뒤에 위치하며, 블록이 할당되지 않은 상태를 나타냄
free_listp += (4 * WSIZE); // 첫번째 가용 블록의 bp
// 힙을 CHUNKSIZE bytes로 확장
if (extend_heap(CHUNKSIZE / WSIZE) == NULL)
return -1;
return 0;
}3) 가용 블록에 할당하기
- (mm_malloc과 extend_heap 함수는 Implicit List와 동일하다.)
가용 블록 검색
- 가용 리스트의 첫번째 블록부터 탐색을 시작한다.
- 현재 필요한 크기인
asize를 담을 수 있는 블록을 찾을 때까지 탐색을 이어간다. (First-fit)
static void *find_fit(size_t asize)
{
void *bp = free_listp;
while (bp != NULL) // 다음 가용 블럭이 있는 동안 반복
{
if ((asize <= GET_SIZE(HDRP(bp)))) // 적합한 사이즈의 블록을 찾으면 반환
return bp;
bp = GET_SUCC(bp); // 다음 가용 블록으로 이동
}
return NULL;
}
할당
- 할당할 블록을 가용 리스트에서 제거한다.
- 사용하고 남은 사이즈만큼 또다른 가용 블록으로 만들고 가용 리스트에 추가한다.
- 할당 - LIFO 순서 정책
static void place(void *bp, size_t asize)
{
splice_free_block(bp); // free_list에서 해당 블록 제거
size_t csize = GET_SIZE(HDRP(bp)); // 현재 블록의 크기
if ((csize - asize) >= (2 * DSIZE)) // 차이가 최소 블록 크기 16보다 같거나 크면 분할
{
PUT(HDRP(bp), PACK(asize, 1)); // 현재 블록에는 필요한 만큼만 할당
PUT(FTRP(bp), PACK(asize, 1));
PUT(HDRP(NEXT_BLKP(bp)), PACK((csize - asize), 0)); // 남은 크기를 다음 블록에 할당(가용 블록)
PUT(FTRP(NEXT_BLKP(bp)), PACK((csize - asize), 0));
add_free_block(NEXT_BLKP(bp)); // 남은 블록을 free_list에 추가
}
else
{
PUT(HDRP(bp), PACK(csize, 1)); // 해당 블록 전부 사용
PUT(FTRP(bp), PACK(csize, 1));
}
}
- 할당 - 주소 순서 정책
- 주소 순서 정책을 사용할 경우에는 해당 블록을 전부 사용할 때만 가용 리스트에서 해당 블록을 제거한다.
- 해당 블록의 일부만 사용할 때는, 현재 사용하는 블록의
predeccessor와successor를 새로 만들어지는 가용 블록에 연결되도록 변경하고 사이즈를 남은 크기로 변경하는 방법을 사용해서 ‘가용 리스트에서 제거하고 추가하는 과정’을 줄일 수 있다.
static void place(void *bp, size_t asize)
{
size_t csize = GET_SIZE(HDRP(bp)); // 현재 블록의 크기
if ((csize - asize) >= (2 * DSIZE)) // 차이가 최소 블록 크기 16보다 같거나 크면 분할
{
PUT(HDRP(bp), PACK(asize, 1)); // 현재 블록에는 필요한 만큼만 할당
PUT(FTRP(bp), PACK(asize, 1));
bp = NEXT_BLKP(bp); // 다음 블록으로 이동
PUT(HDRP(bp), PACK((csize - asize), 0)); // 남은 크기를 다음 블록에 할당(가용 블록)
PUT(FTRP(bp), PACK((csize - asize), 0));
GET_SUCC(bp) = GET_SUCC(PREV_BLKP(bp)); // 루트였던 블록의 PRED를 추가된 블록으로 연결
if (PREV_BLKP(bp) == free_listp)
{
free_listp = bp;
}
else
{
GET_PRED(bp) = GET_PRED(PREV_BLKP(bp));
GET_SUCC(GET_PRED(PREV_BLKP(bp))) = bp;
}
if (GET_SUCC(bp) != NULL) // 다음 가용 블록이 있을 경우만
GET_PRED(GET_SUCC(bp)) = bp;
}
else
{
splice_free_block(bp);
PUT(HDRP(bp), PACK(csize, 1)); // 해당 블록 전부 사용
PUT(FTRP(bp), PACK(csize, 1));
}
}
가용 리스트에서 제거
- 할당할 블록을 가용 리스트에서 제거한다.
// 가용 리스트에서 bp에 해당하는 블록을 제거하는 함수
static void splice_free_block(void *bp)
{
if (bp == free_listp) // 분리하려는 블록이 free_list 맨 앞에 있는 블록이면 (이전 블록이 없음)
{
free_listp = GET_SUCC(free_listp); // 다음 블록을 루트로 변경
return;
}
// 이전 블록의 SUCC을 다음 가용 블록으로 연결
GET_SUCC(GET_PRED(bp)) = GET_SUCC(bp);
// 다음 블록의 PRED를 이전 블록으로 변경
if (GET_SUCC(bp) != NULL) // 다음 가용 블록이 있을 경우만
GET_PRED(GET_SUCC(bp)) = GET_PRED(bp);
}
가용 리스트에 추가
- 새로운 가용 블록을 가용 리스트에 추가한다.
- 가용 리스트에 추가 - LIFO 순서 정책
// 가용 리스트의 맨 앞에 현재 블록을 추가하는 함수
static void add_free_block(void *bp)
{
GET_SUCC(bp) = free_listp; // bp의 SUCC은 루트가 가리키던 블록
if (free_listp != NULL) // free list에 블록이 존재했을 경우만
GET_PRED(free_listp) = bp; // 루트였던 블록의 PRED를 추가된 블록으로 연결
free_listp = bp; // 루트를 현재 블록으로 변경
}
- 가용 리스트에 추가 - 주소 순서 정책
// 가용 리스트에서 주소 오름차순에 맞게 현재 블록을 추가하는 함수
static void add_free_block(void *bp)
{
void *currentp = free_listp;
if (currentp == NULL)
{
free_listp = bp;
GET_SUCC(bp) = NULL;
return;
}
while (currentp < bp) // 검사중인 주소가 추가하려는 블록의 주소보다 작을 동안 반복
{
if (GET_SUCC(currentp) == NULL || GET_SUCC(currentp) > bp)
break;
currentp = GET_SUCC(currentp);
}
GET_SUCC(bp) = GET_SUCC(currentp); // 루트였던 블록의 PRED를 추가된 블록으로 연결
GET_SUCC(currentp) = bp; // bp의 SUCC은 루트가 가리키던 블록
GET_PRED(bp) = currentp; // bp의 SUCC은 루트가 가리키던 블록
if (GET_SUCC(bp) != NULL) // 다음 가용 블록이 있을 경우만
{
GET_PRED(GET_SUCC(bp)) = bp;
}
}4) 블록 반환하기
- (mm_free 함수는 Implicit List와 동일하다.)
병합
- 현재 가용 상태로 변하는 블록의 인접 블록이 가용 상태인 경우, 해당 인접 블록을 가용 리스트에서 제거한다.
- 가용 리스트에서 제거한 인접 블록을 현재 가용 상태로 변하는 블록과 합친 후 가용 리스트에 추가한다.
- 병합 - LIFO 순서 정책
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp))); // 이전 블록 할당 상태
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); // 다음 블록 할당 상태
size_t size = GET_SIZE(HDRP(bp)); // 현재 블록 사이즈
if (prev_alloc && next_alloc) // 모두 할당된 경우
{
add_free_block(bp); // free_list에 추가
return bp; // 블록의 포인터 반환
}
else if (prev_alloc && !next_alloc) // 다음 블록만 빈 경우
{
splice_free_block(NEXT_BLKP(bp)); // 가용 블록을 free_list에서 제거
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0)); // 현재 블록 헤더 재설정
PUT(FTRP(bp), PACK(size, 0)); // 다음 블록 푸터 재설정 (위에서 헤더를 재설정했으므로, FTRP(bp)는 합쳐질 다음 블록의 푸터가 됨)
}
else if (!prev_alloc && next_alloc) // 이전 블록만 빈 경우
{
splice_free_block(PREV_BLKP(bp)); // 가용 블록을 free_list에서 제거
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); // 이전 블록 헤더 재설정
PUT(FTRP(bp), PACK(size, 0)); // 현재 블록 푸터 재설정
bp = PREV_BLKP(bp); // 이전 블록의 시작점으로 포인터 변경
}
else // 이전 블록과 다음 블록 모두 빈 경우
{
splice_free_block(PREV_BLKP(bp)); // 이전 가용 블록을 free_list에서 제거
splice_free_block(NEXT_BLKP(bp)); // 다음 가용 블록을 free_list에서 제거
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); // 이전 블록 헤더 재설정
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0)); // 다음 블록 푸터 재설정
bp = PREV_BLKP(bp); // 이전 블록의 시작점으로 포인터 변경
}
add_free_block(bp); // 현재 병합한 가용 블록을 free_list에 추가
return bp; // 병합한 가용 블록의 포인터 반환
}
- 병합 - 주소 순서 정책
- 주소 순서 정책을 사용할 경우에는 병합 전 가용 블록과 병합 후 가용 블록의 bp가 다를 경우에만
splice_free_block과add_free_block함수를 호출한다.
- 주소 순서 정책을 사용할 경우에는 병합 전 가용 블록과 병합 후 가용 블록의 bp가 다를 경우에만
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp))); // 이전 블록 할당 상태
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); // 다음 블록 할당 상태
size_t size = GET_SIZE(HDRP(bp)); // 현재 블록 사이즈
if (prev_alloc && next_alloc) // 모두 할당된 경우
{
add_free_block(bp); // free_list에 추가
return bp; // 블록의 포인터 반환
}
else if (prev_alloc && !next_alloc) // 다음 블록만 빈 경우
{
splice_free_block(NEXT_BLKP(bp)); // 가용 블록을 free_list에서 제거
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0)); // 현재 블록 헤더 재설정
PUT(FTRP(bp), PACK(size, 0)); // 다음 블록 푸터 재설정 (위에서 헤더를 재설정했으므로, FTRP(bp)는 합쳐질 다음 블록의 푸터가 됨)
add_free_block(bp);
}
else if (!prev_alloc && next_alloc) // 이전 블록만 빈 경우
{
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); // 이전 블록 헤더 재설정
PUT(FTRP(bp), PACK(size, 0)); // 현재 블록 푸터 재설정
bp = PREV_BLKP(bp); // 이전 블록의 시작점으로 포인터 변경
}
else // 이전 블록과 다음 블록 모두 빈 경우
{
splice_free_block(NEXT_BLKP(bp)); // 다음 가용 블록을 free_list에서 제거
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0)); // 이전 블록 헤더 재설정
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0)); // 다음 블록 푸터 재설정
bp = PREV_BLKP(bp); // 이전 블록의 시작점으로 포인터 변경
}
return bp; // 병합한 가용 블록의 포인터 반환
}‘5) 재할당하기’는 Implicit List와 동일하다.
🔥 ’주소 순서’ 정책 vs ‘LIFO 순서’ 정책
- 주소 순서를 사용하는 것이 LIFO 순서를 사용하는 경우보다 더 좋은 메모리 이용도를 가진다.
- 가용 리스트를 주소 순서로 관리하게 되면 블록을 반환할 때 주소에 맞는 위치에 삽입하기 위해서 가용 리스트를 검색하는 시간이 추가적으로 필요하지만, LIFO 정책에 비하여 메모리 단편화가 줄어들어든다.
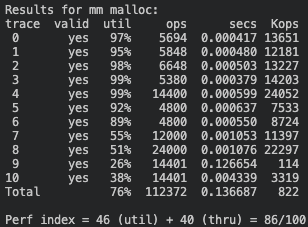
3. Segregated List (Segregated-fits)
👇🏻 Github에서 'Segregated-fits' 전체 코드 보기
🧮 Score: 86점 (이용도 46 + 처리량 40)
💡 Segregated-fits 기본 아이디어
1) 다수의 가용 리스트 활용
- 가용 리스트를 여러 개 만들고, 하나의 가용 리스트에는 비슷한 크기의 블록들만 저장한다.
- 각 가용 리스트의 범위를 나누는 기준은 2의 거듭 제곱 크기를 기준으로 분할한다.
- 가용 리스트 분할 기준 예시
- 클래스 0: 16바이트 ~ 32바이트
- 클래스 1: 32바이트 ~ 64바이트
- 클래스 2: 64바이트 ~ 128바이트
- 클래스 3: 128바이트 ~ 256바이트
- 클래스 4: 256바이트 ~ 512바이트
- 클래스 5: 512바이트 ~ 1024바이트
- 클래스 6: 1024바이트 ~ 2048바이트
- 클래스 7: 2048바이트 ~ 4096바이트
- 클래스 8: 4096바이트 ~ 8192바이트
- 클래스 9: 8192 이상 …
- 가용 리스트 분할 기준 예시
- 가용 블록들을 여러 개의 리스트로 관리하면 하나의 리스트에는 더 적은 수의 블록이 담기므로, 할당할 때 더 적은 수의 목록을 탐색하게 되어 탐색 시간이 줄어든다.
- 최적의 가용 리스트 개수 결정
- 최적의 가용 리스트 개수를 결정하려면, 블록의 크기 분포를 분석하여 크기 범위와 개수를 조정해야 한다.
- 이 과제에서는 가용 리스트의 개수를 12개로 적용했다.
2) 블록 할당
- 할당하려는 블록의 크기에 맞는 가용 리스트를 찾는다.
- 해당 가용 리스트를 처음부터 검색해서
크기가 맞는 첫번째 가용 블록을 선택한다. (First fit) - 가용 리스트에 적합한 가용 블록이 없다면 다음 가용 리스트로 이동해서 탐색을 이어간다.
- 할당하면서 또다른 가용 블록이 생기면 해당 가용 블록의 크기에 맞는 가용 리스트에 추가한다.
3) 블록 반환
- (Implicit List와 동일) 블록이 반환되면 주소상으로 인접한 블록을 확인해서 빈 블록이 있다면 연결하여 더 큰 블록으로 만들어서 가용 블록으로 만든다.
- 만들어진 가용 블록의 크기에 맞는 가용 리스트에 삽입한다.
🖥 Segregated-fits 구현
1) Segregated List 관련 매크로 정의
- 가용 리스트의 개수를 나타낼 상수와 가용 리스트의 루트를 반환하는 매크로를 정의한다.
- (이외의 상수 및 매크로는 Explicit List와 동일하다.)
// 가용 리스트의 개수
#define SEGREGATED_SIZE (12)
// 해당 가용 리스트의 루트
#define GET_ROOT(class) (*(void **)((char *)(heap_listp) + (WSIZE * class)))2) 힙 & Segregated List 생성하기
- 프롤로그 Header와 Footer 사이에 Segregated List들의 각 root 블록의 주소를 담을 워드를 배정한다.
- 초기에는 가용 리스트가 존재하지 않으므로 NULL로 초기화한다.
int mm_init(void)
{
// 초기 힙 생성
if ((heap_listp = mem_sbrk((SEGREGATED_SIZE + 4) * WSIZE)) == (void *)-1) // 8워드 크기의 힙 생성, heap_listp에 힙의 시작 주소값 할당(가용 블록만 추적)
return -1;
PUT(heap_listp, 0); // 정렬 패딩
PUT(heap_listp + (1 * WSIZE), PACK((SEGREGATED_SIZE + 2) * WSIZE, 1)); // 프롤로그 Header (크기: 헤더 1 + 푸터 1 + segregated list 크기)
for (int i = 0; i < SEGREGATED_SIZE; i++)
PUT(heap_listp + ((2 + i) * WSIZE), NULL);
PUT(heap_listp + ((SEGREGATED_SIZE + 2) * WSIZE), PACK((SEGREGATED_SIZE + 2) * WSIZE, 1)); // 프롤로그 Footer
PUT(heap_listp + ((SEGREGATED_SIZE + 3) * WSIZE), PACK(0, 1)); // 에필로그 Header: 프로그램이 할당한 마지막 블록의 뒤에 위치
heap_listp += (2 * WSIZE);
if (extend_heap(4) == NULL)
return -1;
if (extend_heap(CHUNKSIZE / WSIZE) == NULL)
return -1;
return 0;
}3) 가용 블록에 할당하기
- (mm_malloc과 extend_heap, place 함수는 Explicit List(LIFO)와 동일하다.)
가용 블록 검색
- 가용 블록을 탐색할 가용 리스트를 찾는다. (
get_class함수 호출) - 위에서 찾은 가용 리스트의 루트 블록부터 탐색을 시작한다.
- 현재 필요한 크기인
asize를 담을 수 있는 블록을 찾을 때까지 탐색을 이어간다. (First-fit) - 가용 리스트에 적합한 블록이 존재하지 않으면 다음 가용 리스트로 이동해서 탐색을 이어 나간다.
static void *find_fit(size_t asize)
{
int class = get_class(asize);
void *bp = GET_ROOT(class);
while (class < SEGREGATED_SIZE) // 현재 탐색하는 클래스가 범위 안에 있는 동안 반복
{
bp = GET_ROOT(class);
while (bp != NULL)
{
if ((asize <= GET_SIZE(HDRP(bp)))) // 적합한 사이즈의 블록을 찾으면 반환
return bp;
bp = GET_SUCC(bp); // 다음 가용 블록으로 이동
}
class += 1;
}
return NULL;
}
가용 리스트에서 제거
- 제거할 블록이 있는 가용 리스트를 찾고(
get_class함수 호출) 해당 가용 리스트에서 제거한다.
// 가용 리스트에서 bp에 해당하는 블록을 제거하는 함수
static void splice_free_block(void *bp)
{
int class = get_class(GET_SIZE(HDRP(bp)));
if (bp == GET_ROOT(class)) // 분리하려는 블록이 free_list 맨 앞에 있는 블록이면 (이전 블록이 없음)
{
GET_ROOT(class) = GET_SUCC(GET_ROOT(class)); // 다음 블록을 루트로 변경
return;
}
// 이전 블록의 SUCC을 다음 가용 블록으로 연결
GET_SUCC(GET_PRED(bp)) = GET_SUCC(bp);
// 다음 블록의 PRED를 이전 블록으로 변경
if (GET_SUCC(bp) != NULL) // 다음 가용 블록이 있을 경우만
GET_PRED(GET_SUCC(bp)) = GET_PRED(bp);
}
가용 리스트에 추가
- 새로운 가용 블록을 적합한 가용 리스트에 추가한다.
// 적합한 가용 리스트를 찾아서 맨 앞에 현재 블록을 추가하는 함수
static void add_free_block(void *bp)
{
int class = get_class(GET_SIZE(HDRP(bp)));
GET_SUCC(bp) = GET_ROOT(class); // bp의 해당 가용 리스트의 루트가 가리키던 블록
if (GET_ROOT(class) != NULL) // list에 블록이 존재했을 경우만
GET_PRED(GET_ROOT(class)) = bp; // 루트였던 블록의 PRED를 추가된 블록으로 연결
GET_ROOT(class) = bp;
}
적합한 가용 리스트 탐색
- 첫번째 가용 리스트의 최소 크기는 블록의 최소 크기인 16bytes로 설정하고,
다음 단계로 넘어갈수록 최소 크기가 이전 가용 리스트의 2배가 될 때
현재 size에 적합한 가용 리스트를 찾는다.
// 적합한 가용 리스트를 찾는 함수
int get_class(size_t size)
{
if (size < 16) // 최소 블록 크기는 16바이트
return -1; // 잘못된 크기
// 클래스별 최소 크기
size_t class_sizes[SEGREGATED_SIZE];
class_sizes[0] = 16;
// 주어진 크기에 적합한 클래스 검색
for (int i = 0; i < SEGREGATED_SIZE; i++)
{
if (i != 0)
class_sizes[i] = class_sizes[i - 1] << 1;
if (size <= class_sizes[i])
return i;
}
// 주어진 크기가 마지막 클래스의 범위를 넘어갈 경우, 마지막 클래스로 처리
return SEGREGATED_SIZE - 1;
}
‘4) 블록 반환하기’와 ‘5) 재할당하기’는 Explicit List(LIFO)와 동일하다.
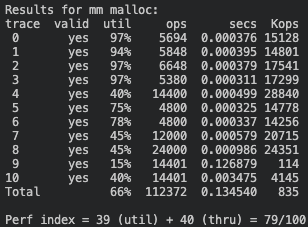
4. Segregated List (Buddy-System)
👇🏻 Github에서 'Buddy-System' 전체 코드 보기
🧮 Score: 79점 (이용도 39 + 처리량 40)
이 구현 방식은 힙의 메모리를 많이 차지하게 되어 mem_sbrk를 실패해 테스트 케이스를 통과하지 못한다.
아래의 결과는 config.h 파일의 MAX_HEAP을 (20*(1<<21))로 늘려주고 테스트한 결과이다.
💡 Buddy-System 기본 아이디어
1) 동일한 블록 크기를 갖는 다수의 가용 리스트 활용
- Segregated-fits 방식과 다수의 가용 리스트를 활용한다는 점은 동일하지만, 한 가용 리스트에 들어있는 블록의 크기가 모두 동일하다는 차이가 있다.
- 각 블록은 2의 거듭 제곱 크기이다.
2) 블록 할당
- 할당하려는 size를 2의 n승이 되도록 올림 처리한 후 크기에 맞는 블록을 탐색한다.
- 할당할 블록을 탐색할 때는 Segregated-fits와 동일하게 크기에 맞는 가용 리스트에서 탐색을 진행하고, 블록이 존재하지 않는다면 다음 가용 리스트로 이동해서 탐색을 이어나간다.
- 선택한 블록의 크기가 할당하려는 size와 다르다면 필요한 사이즈의 블록이 될 때까지 반으로 나누고 사용하지 않는 부분은 나눠진 크기에 적합한 가용 리스트에 추가한다.
3) 블록 반환
- Buddy-System의 장점인 빠른 검색과 연결을 가능하게 해주는 부분은 블록 반환 시 발생하는 병합에 있다.
- 블록이 분할되면서 생기는 두개의 블록은 서로가 서로의
buddy가 된다. - 각 블록의 bp를 활용해서 서로의
buddy를 찾을 수 있다. - 반환하는 블록의
buddy가 가용 상태인지 확인해서 가용 상태라면 병합한다. - 인접한 블록이더라도
buddy가 아니라면 병합하지 않는다.
🖥 Buddy-System 구현
1) Buddy-System 관련 매크로 정의
- Segregated-fits에서 12를 할당했던
SEGREGATED_SIZE를 20으로 늘려주었다. - Buddy-System에서는 블록의 Footer가 필요하지 않으니 제거한다!
- (이외의 상수 및 매크로는 Segregated-fits와 동일하다.)
#define SEGREGATED_SIZE (20) // segregated list의 class 개수
삭제 👉🏻 #define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)2) 힙 & Segregated List 생성하기
- (Segregated-fits와 동일하다.)
3) 가용 블록에 할당하기
- (find_fit과 splice_free_block, add_free_block 함수는 Segregated-fits와 동일하다.)
- 요청 받은 size에 헤더와 푸터 크기인 8bytes를 더하고 나서 2의 n승이 되도록 올림 처리한 후 크기에 맞는 가용 블록을 탐색한다.
void *mm_malloc(size_t size)
{
size_t asize = 16; // 조정된 블록 사이즈
size_t extendsize; // 확장할 사이즈
char *bp;
if (size == 0) // 잘못된 요청 분기
return NULL;
/* 사이즈 조정 */
while (asize < size + DSIZE) // 요청받은 size에 8(헤더와 푸터 크기)를 더한 값을 2의 n승이 되도록 올림
{
asize <<= 1;
}
/* 가용 블록 검색 */
if ((bp = find_fit(asize)) != NULL)
{
place(bp, asize); // 할당
return bp; // 새로 할당된 블록의 포인터 리턴
}
/* 적합한 블록이 없을 경우 힙확장 */
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize / WSIZE)) == NULL)
return NULL;
place(bp, asize);
return bp;
}
할당
- 할당할 블록을 탐색할 때는 Segregated-fits와 동일하게 크기에 맞는 가용 리스트에서 탐색을 진행하고, 블록이 존재하지 않는다면 다음 가용 리스트로 이동해서 탐색을 이어나간다.
- 선택한 블록의 크기가 할당하려는 size와 다르다면 필요한 사이즈의 블록이 될 때까지 반으로 나누고 사용하지 않는 부분은 나눠진 크기에 적합한 가용 리스트에 추가한다.
static void place(void *bp, size_t asize) // 할당할 위치의 bp, 사용할 양
{
splice_free_block(bp); // free_list에서 해당 블록 제거
size_t csize = GET_SIZE(HDRP(bp)); // 사용하려는 블록의 크기
while (asize != csize) // 사용하려는 asize와 블록의 크기 csize가 다르면
{
csize >>= 1; // 블록의 크기를 반으로 나눔
PUT(HDRP(bp + csize), PACK(csize, 0)); // 뒷부분을 가용 블록으로 변경
add_free_block(bp + csize); // 뒷부분을 가용 블록 리스트에 추가
}
PUT(HDRP(bp), PACK(csize, 1)); // 크기가 같아지면 해당 블록 사용 처리
}
적합한 가용 리스트 탐색
- size를 2의 배수가 되도록 올림 처리하고 해당하는 가용 리스트를 찾는다.
// 적합한 가용 리스트를 찾는 함수
int get_class(size_t size)
{
int next_power_of_2 = 1;
int class = 0;
while (next_power_of_2 < size && class + 1 < SEGREGATED_SIZE)
{
next_power_of_2 <<= 1;
class ++;
}
return class;
}4) 블록 반환하기
반환
- 블록의 Footer 정보는 필요하지 않으므로 Header의 사이즈 정보만 갱신한다.
void mm_free(void *bp)
{
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0));
coalesce(bp);
}
병합
- 모든 블록의 크기가 2의 거듭제곱 크기라는 것을 이용해서, 현재 반환되는 블록의
buddy를 찾을 수 있다.buddy의 블록 포인터는 현재 블록의 포인터에서 size만큼 빼거나 더해서 구할 수 있다.- size만큼 빼야 하는지 더해야 하는지 파악하려면 현재
buddy가 왼쪽 버디인지, 오른쪽 버디인지 알아야 한다. - 현재 블록의 주소에서 메모리 블록이 시작하는 주소를 빼고, 그 값이 블록의 사이즈를 비트로 나타낸 것과 비교했을 때 겹치는 비트가 있다면 현재 블록은 오른쪽
buddy에 해당한다.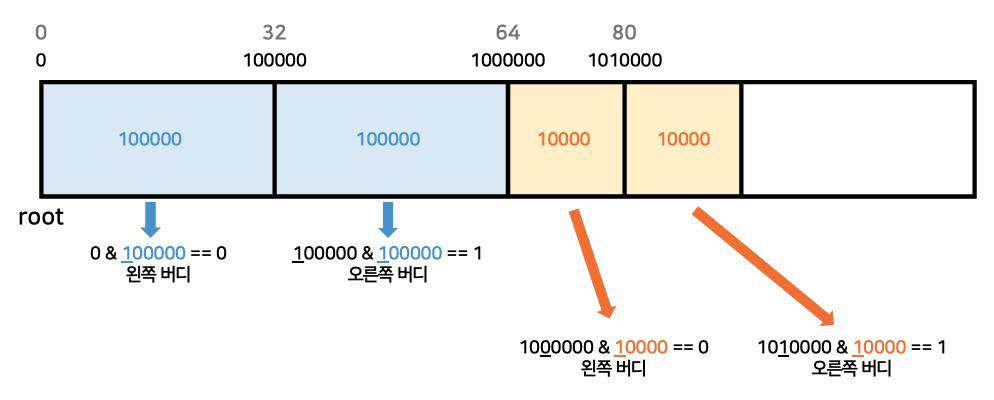
- 찾아낸 버디가 가용상태이고, 분할되지 않은 상태라면 현재 블록과 병합한다.
(버디가 분할되어 있다면 현재 블록과 사이즈가 다를 것이므로 사이즈를 비교해서 알아낼 수 있다.) - 할당 상태이거나 분할된 버디를 만나기 전까지 계속해서 버디끼리 합쳐나가며 블록의 크기를 최대로 만든다.
static void *coalesce(void *bp)
{
add_free_block(bp); // 현재 블록을 free list에 추가
size_t csize = GET_SIZE(HDRP(bp)); // 반환할 사이즈
void *root = heap_listp + (SEGREGATED_SIZE + 1) * WSIZE; // 실제 메모리 블록들이 시작하는 위치
void *left_buddyp; // 왼쪽 버디의 bp
void *right_buddyp; // 오른쪽 버디의 bp
while (1)
{
// 좌우 버디의 bp 파악
if ((bp - root) & csize) // 현재 블록에서 힙까지의 메모리 합(bp - root)과 csize가 중복되는 비트가 있다면 현재 블록은 오른쪽 버디에 해당
{
left_buddyp = bp - csize;
right_buddyp = bp;
}
else
{
right_buddyp = bp + csize;
left_buddyp = bp;
}
// 양쪽 버디가 모두 가용 상태이고, 각 사이즈가 동일하면 (각 버디가 분할되어있지 않으면)
if (!GET_ALLOC(HDRP(left_buddyp)) && !GET_ALLOC(HDRP(right_buddyp)) && GET_SIZE(HDRP(left_buddyp)) == GET_SIZE(HDRP(right_buddyp)))
{
splice_free_block(left_buddyp); // 양쪽 버디를 모두 가용 리스트에서 제거
splice_free_block(right_buddyp);
csize <<= 1; // size를 2배로 변경
PUT(HDRP(left_buddyp), PACK(csize, 0)); // 왼쪽 버디부터 size만큼 가용 블록으로 변경
add_free_block(left_buddyp); // 가용 블록으로 변경된 블록을 free list에 추가
bp = left_buddyp;
}
else
break;
}
return bp;
}
‘5) 재할당하기’는 Explicit List(LIFO)와 동일하다.
5. Segregated List (기타 방식)
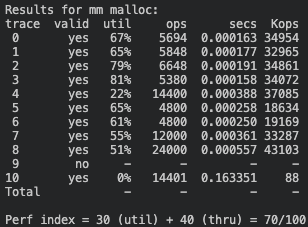
1) Simple-Segregated Storage 방식
Github에서 'Simple-Segregated Storage' 전체 코드 보기
🧮 Score: 70점 (이용도 30 + 처리량 40)
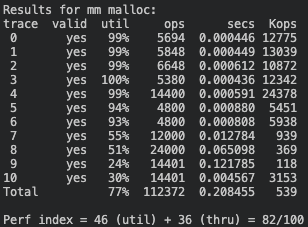
2) Address-Ordered 방식
Github에서 'Address-Ordered' 전체 코드 보기
🧮 Score: 82점 (이용도 46 + 처리량 36)
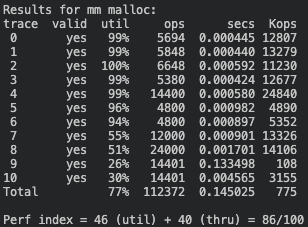
3) Size-Ordered 방식
Github에서 'Size-Ordered' 전체 코드 보기
🧮 Score: 86점 (이용도 46 + 처리량 40)
'C언어' 카테고리의 다른 글
| [c언어] Proxy Lab :: Proxy Server 구현하기 (Sequential proxy, Concurrent proxy, Caching) (5) | 2023.04.20 |
|---|---|
| [c언어] Red-Black Tree 구현하기 (0) | 2023.04.06 |
| MacOS에서 Ubuntu 개발 환경 설치하기 (AWS, VSC) (0) | 2023.03.31 |